


Что такое генеративный искусственный интеллект?
Большое ускорение в этой области, произошедшее в последние годы, объясняется двумя основными причинами:
Разработанные модели наконец-то достигли результатов человеческого уровня, или даже сверхчеловеческого уровня. Вычислительные процессы в облаке стали значительно дешевле.
Эти две причины заставили исследовательские компании открыть доступ разработчикам для создания приложений.
В этой статье я сфокусируюсь на технологиях, которые актуальны для случаев использования текста и визуальных образов.

Ключевые концепции алгоритмов ИИ
Ключевые концепции
Прежде чем приступить к изучению различных моделей, существующих сегодня на рынке, давайте объясним три концепции, которые повторяются в различных алгоритмах.
Трансформатор
Архитектура нейронной сети, изобретенная Google в 2017 году (впервые описана в статье “Attention Is All You Need”). Она использует механизм внимания – то есть модель может быть обучена читать много слов (предложение или полный абзац), а также их контекст – она обращает внимание на связь слова с другим словом. Для этого используются кодировщики и декодировщики с механизмом внимания – для каждой входной части учитывается релевантность других частей.
Кодировщик
Компонент, который принимает входную последовательность, например, текст, и преобразует ее в размерное пространство (математическое представление, например, вектор).
Декодер
Компонент, который превращает вектор кодера в выходную последовательность.
Генерация текста
Целью разработки моделей генерирования текста является поддержка различных задач NLP, но в целом – создание текста, похожего на человеческий. Наиболее распространенными случаями использования являются: творческое письмо, генерация кода, создание контента и обслуживание клиентов. В интернете существует несколько обученных моделей, самой популярной из которых на данный момент является GPT-3.
GPT-3
Разработанная OpenAI, проиндексировала 45 ТБ текстовых данных (только на английском языке) с 175 миллиардами параметров. Параметры – это части модели, выученные из исторических данных обучения, и по сути определяют навыки модели в решении задачи, например, генерации текста.
GPT-3 – это языковая модель, то есть она способна угадывать, каким должно быть следующее слово в предложении. Что делает эту модель уникальной, так это отсутствие тонкой настройки – что звучит странно, верно? Обычно чем больше мы настраиваем модель под конкретный случай использования, тем больше получаем хороших результатов.
Ну, большинство моделей NLP нуждаются в тонкой настройке под определенную задачу и определенные данные – например, угадывание следующего слова. Это был первый случай, когда большая модель без наблюдения победила модель с тонкой настройкой под конкретную задачу.
GPT-3 обучался только на задаче угадывания следующего слова, таким образом, он узнал, как работает язык, поэтому он может выполнять множество других задач НЛП.
Его модель основана на Transformers, но только со слоями декодера, которые обучались на 300 миллиардах лексем (слов или их частей), собранных в Интернете, а также в книгах.
Эта модель наделала столько шума в мире, что за столь короткое время было создано множество инструментов и продуктов с GPT-3.
Другие модели, существующие для различных целей и набирающие обороты, это:
LaMDA от Google
Ее основное назначение – заполнение и составление текста (чат-боты и т.д.). Этот модуль построен на модели Transformer, обученной на данных диалогов и разговоров.
BERT
Основное назначение – задачи классификации, извлечение сущностей, а также ответы на вопросы. Он основан на Transformer, но только с кодирующими слоями, то есть использует только слой внимания, поэтому такая модель может быть легко обучена на разных языках.
Wu-Dao от Пекинской академии
Построена на аналогичной архитектуре GPT-3, но имеет 1,75 триллиона параметров. Он обучался на 4,9 терабайтах изображений и текстов (китайских и английских) и считается самым большим модулем ИИ на данный момент.
GPT-J
Построен на аналогичной архитектуре GPT-3, но обучен на меньшем, но высококачественном наборе данных с ~6 миллиардами параметров. С точки зрения производительности и точности GPT-3 выигрывает. Преимущество GPT-J в том, что он имеет открытый исходный код и бесплатен для использования.
Генерация изображения
Эра до диффузионных моделей. Генеративные модели изображений стали более модными после появления в 2014 году генеративных адверсарных сетей (GAN). GAN – это интеллектуальный способ обучения с двумя субмоделями, которые работают в соревновании друг с другом. Модель генератора обучается генерировать новые примеры, а модель дискриминатора пытается классифицировать примеры как настоящие или поддельные. Обе модели обучаются вместе в игре с нулевой суммой, пока дискриминатор не потерпит неудачу в 50% испытаний.
Проблема этой модели в том, что ее очень трудно обучить делать что-то творческое и интересное. Как только она решила проблему и победила в игре, нет стимула генерировать что-то совсем другое.
Для решения этой проблемы исследователи придумали диффузионную модель. Модель, которая берет фрагмент данных и постепенно добавляет к нему шум, пока он не перестает быть узнаваемым. Затем она пытается восстановить изображение из этой точки в исходную форму. Таким образом, модель учится генерировать изображение из любых данных. Когда вы обучаете эту модель, вы можете тренировать ее на разных изображениях с разным количеством шума. Таким образом, модель учится предсказывать для нового изображения, каким будет шум в заданном уровне, который мы хотим получить.

“Искусство для людей…“
В январе 2021 года OpenAI представила оригинального DALL-E, инструмент произвел впечатление на экспертов ИИ и общественность благодаря своей способности превращать любое письменное описание в уникальный образ.
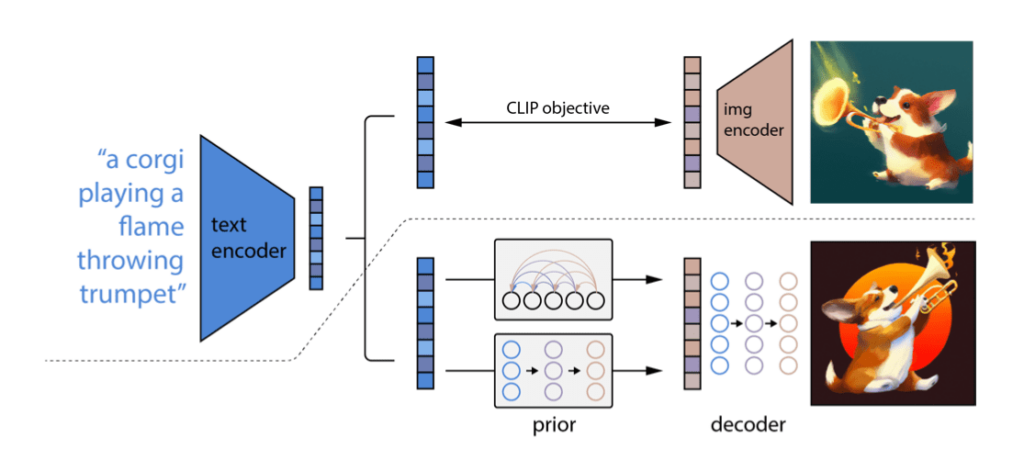
DALL-E2
Он может генерировать новое уникальное изображение, добавлять новую информацию к существующему изображению или создавать различные вариации изображения. Архитектура состоит из двух основных частей:
- Предварительный преобразователь для преобразования надписи в изображение (вектор).
- Декодер, который превращает представление изображения в изображение.
Представление текста и изображения происходит с помощью другой технологии под названием CLIP: нейросетевая модель, которая возвращает наилучшую подпись, описывающую изображение. Это контрастная модель, то есть она не классифицирует изображение, а сопоставляет его с подписью. Она обучается на парах изображений и подписей из Интернета. Используя два кодировщика, которые преобразуют изображение и текст в их представление, он находит наибольшее значение сходства, пересекающее два вектора (над пунктирной линией показан процесс обучения CLIP).
Приор, который является диффузионным режимом, берет встраивание текста CLIP и создает встраивание изображения CLIP.
Декодер также представляет собой диффузионную модель в сочетании с моделью GLIDE, которая поддерживает встраивание изображений. Таким образом, модель декодера в данном случае соответствует исходному изображению, а также надписи и вкраплениям CLIP. (Ниже пунктирной линией показан процесс преобразования текста в изображение с предварительным и декодером).
В настоящее время DALL-E2 доступен в виде API для всех желающих.
Stable Diffusion
Альтернатива DALL-E2 с открытым исходным кодом, разработанная компанией stability.ai. Основана на моделях стабильной диффузии. Режим был обучен на более чем 5 миллиардах пар изображение-текст, взятых из LAION-5B, общедоступного набора данных, полученного от Common Crawl (некоммерческой организации, которая изучает веб-страницы).Чем же он отличается от DALL-E2? Ну, если мне нужно на что-то указать, то это разрешение. Если вам нужно изображение с высоким разрешением, Stable Diffusion может достигать 1024×1024 (!).
Stable Diffusion доступен в виде API.

Midjourney
Независимая исследовательская лаборатория, которая создает изображения из текстовых описаний. Их инструмент в настоящее время находится в стадии открытого бета-тестирования, и у них есть большое сообщество в Discord, которое генерирует с помощью бота командные произведения искусства (да, discord в настоящее время является их пользовательским интерфейсом, чтобы попробовать их сервис). https://discord.gg/midjourney
Генераторы видео
Сгенерировать видео
Существуют проекты, в которых генеративный искусственный интеллект выходит на новый уровень. Генерация видео из текста – очень сложная задача, обусловленная различными факторами, такими как высокие вычислительные затраты, длина видео и отсутствие высококачественных обучающих данных.
Phenaki (от Google)
Этот проект очень амбициозен, поскольку, в отличие от других проектов, он нацелен на создание видео длинной формы. Я бы назвал его “текст в видео”, где вы подробно описываете смысл, который хотите сгенерировать, и он может сгенерировать целое видео из нескольких смыслов. Он также может генерировать видео из неподвижного изображения и текстового описания.
В их работах не так много подробностей об их моделях, но впервые мы имеем исследование о генерации видео в соответствии с подсказками временной переменной, то есть их алгоритм знает, как относиться к сценам как к последовательности времени.
Make-A-Video (by Meta)
Модель, которая генерирует видео из текста. Модель обучалась на 2,3 миллиардах пар текст-изображение и 20 миллионах немаркированных видео.
Imagen Video (по материалам Google Research)
Одним из обещаний этого проекта является создание видео высокого разрешения. Их модель основана на каскадных моделях диффузии, что является эффективным методом масштабирования модели диффузии для получения выходных данных с очень высоким разрешением.
Что дальше?
Сегодня существуют полезные приложения генеративного ИИ для различных сценариев использования, таких как изображения, текст, аудио, код и видео.
Как только разработчики получат доступ к качественным моделям преобразования текста в видео, мы увидим новую волну приложений.
Очень интересным может быть случай, когда он будет развернут в Metaverse и Web3, которые уже включают в себя множество активов цифрового контента.
-
Previous Post
Простой способ оплатить ChatGPT, Midjorney
Читайте также

Объяснение основ нейронных сетей и их значение в различных областях
Введение в нейронные сети Объяснение основ нейронных сетей и их значение в различных областях Нейронные…

Топ аниме нейросетей – превращаем фото в аниме картинку
Топ-9 генераторов ИИ для создания аниме картинок из фото и текста Откройте для себя 9…

Нейросети – изменение цвета волос, подбора причёски и макияжа онлайн.
5 лучших приложений для окрашивания волос с бесплатной виртуальной примеркой в 2023 году Окунитесь в…

Маникюр приложение для дизайна ногтей – примерка ногтей
YouCam Nails – приложение для дизайна ногтей Откройте для себя революционное веб-приложение YouCam Nails, которое…

